Embodied AI


Tra-MoE: Learning Trajectory Prediction Model from Multiple Domains for Adaptive Policy Conditioning
Abstract:
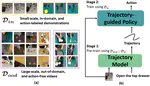
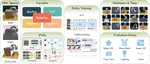
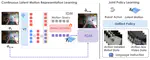
Learning from multiple domains is a primary factor that influences the generalization of a single unified robot system. In this paper, we aim to learn the trajectory prediction model by using broad out-of-domain data to improve its performance and generalization ability.